

Cloudflare Outage Impacts Global Internet Services: A Deep Dive into the Widespread Disruptions
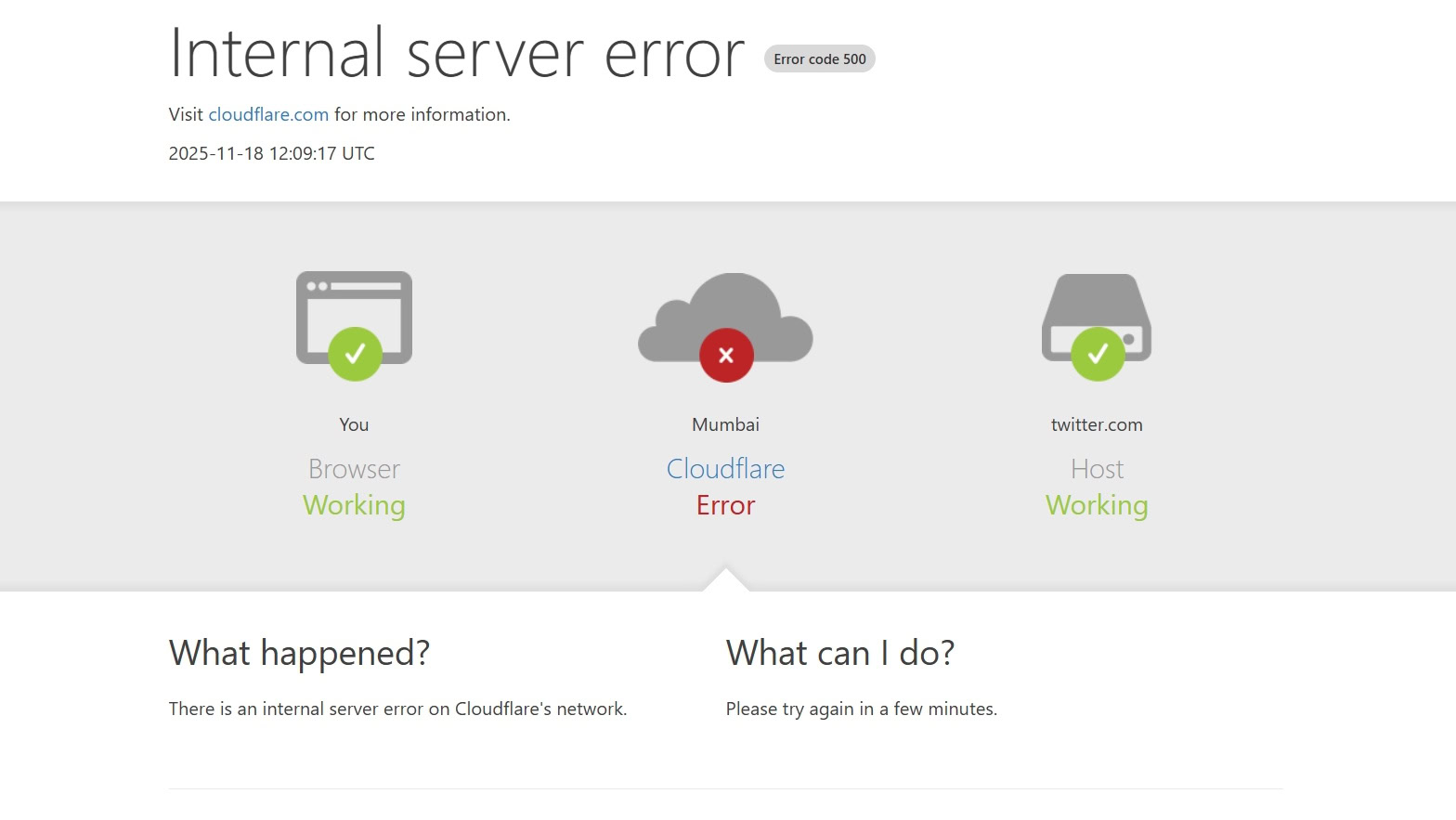
The internet, a tapestry woven with interconnected services and applications, experienced a significant jolt today as Cloudflare, a leading Content Delivery Network (CDN) and Distributed Denial of Service (DDoS) protection provider, confirmed a global outage. This widespread disruption has cascaded, affecting a vast array of websites and online applications that rely on Cloudflare’s robust infrastructure for their online presence and security. Users across the globe have reported being unable to access their favorite platforms, leading to a palpable sense of digital unease.
At the heart of this widespread inconvenience lies a complex technical issue within Cloudflare’s own network. The company, which plays a critical role in ensuring the speed, availability, and security of a substantial portion of the internet, has been actively working to diagnose and resolve the problem. The repercussions are far-reaching, impacting everything from e-commerce giants to small blogs, and from essential business tools to popular social media platforms. The sheer scale of Cloudflare’s reach means that any instability within its system can trigger a domino effect, leaving millions of users disconnected from the digital world they depend on.
This event serves as a stark reminder of the underlying infrastructure that powers our increasingly online lives. While users often take for granted the seamless delivery of web pages and the instant access to services, such outages highlight the critical dependence on companies like Cloudflare. Their role in caching content closer to users, mitigating malicious traffic, and managing DNS requests is fundamental to the modern internet experience. When this foundation falters, the consequences are immediate and widespread.
Understanding the Scope of the Cloudflare Network Disruption
Cloudflare’s extensive global network is designed for resilience and performance. It comprises data centers strategically located in hundreds of cities worldwide, enabling it to serve billions of web requests daily. When this network experiences a significant issue, the impact is amplified due to its pervasive presence. Today’s outage signifies a problem that has transcended regional limitations, affecting users and services on a truly global scale.
The immediate symptom for many users has been an inability to load websites. Error messages, ranging from generic “site not found” or “connection timed out” to more specific Cloudflare-related errors, have become commonplace. This is because when a user attempts to access a website protected by Cloudflare, their request is routed through Cloudflare’s network. If Cloudflare’s servers are experiencing issues, these requests cannot be processed, effectively rendering the websites inaccessible.
The disruption extends beyond mere website loading. Many web applications, including those used for business operations, communication, and entertainment, have also been affected. This is because these applications often rely on Cloudflare for various services, such as API access, security protection, and content delivery. When these services are unavailable, the applications themselves become dysfunctional or completely inaccessible.
Key Services Affected by the Cloudflare Outage
The impact of the Cloudflare outage has been observed across a broad spectrum of online services. While it’s impossible to list every single affected entity, certain categories of websites and applications have been particularly vulnerable due to their reliance on Cloudflare’s infrastructure.
- E-commerce Platforms: Online retailers and marketplaces often use Cloudflare to ensure fast loading times and secure transactions, especially during peak shopping periods. The inability to access these sites directly translates to lost sales and frustrated customers.
- SaaS (Software as a Service) Providers: Many businesses rely on cloud-based software for their daily operations. If these SaaS providers are hosted on or protected by Cloudflare, their services can become unavailable, leading to significant operational disruptions for their clients. This can include customer relationship management (CRM) systems, project management tools, and collaboration platforms.
- Content Management Systems (CMS) and Blogs: Websites built on popular CMS platforms like WordPress, often configured with Cloudflare for performance and security, have also reported issues. This means that news sites, personal blogs, and corporate informational websites have faced access problems.
- Online Gaming and Streaming Services: The demand for low latency and high availability in online gaming and video streaming makes Cloudflare an attractive solution. Outages in this sector lead to interrupted gameplay, buffering issues, and an overall degraded user experience for millions of gamers and viewers.
- Security-Sensitive Applications: Given Cloudflare’s role in DDoS mitigation and web application firewall (WAF) services, any disruption here can leave websites vulnerable to attacks or cause legitimate users to be blocked incorrectly.
The interconnected nature of the internet means that even services not directly hosted on Cloudflare might experience secondary impacts. For instance, if a service relies on an API provided by another company that is itself affected by the Cloudflare outage, then that service will also experience issues. This demonstrates the complex interdependencies within the digital ecosystem.
Cloudflare’s Response and Ongoing Investigation
Cloudflare’s engineering teams have been working with utmost urgency to pinpoint the root cause of the global network issue. The company has been providing regular updates through its status page and other communication channels, acknowledging the problem and detailing their progress in resolving it. Transparency during such critical events is paramount, and Cloudflare has strived to keep its users informed.
The initial reports from Cloudflare indicated a problem within their internal routing configuration. Such issues can be incredibly complex, involving intricate networks of servers and sophisticated software. A misconfiguration, even a seemingly minor one, can have cascading effects across a vast distributed system. The challenge for Cloudflare is not just to fix the immediate problem but also to ensure that the solution is robust and prevents recurrence.
The process of diagnosing and rectifying such a widespread outage involves several critical steps:
- Identification of the Fault: Pinpointing the exact component or configuration that triggered the failure is the first and often most challenging step. This requires deep analysis of network logs, system performance metrics, and traffic patterns.
- Development of a Fix: Once the cause is identified, engineers must develop a precise solution. This might involve rolling back a recent change, deploying a patch, or reconfiguring network elements.
- Testing and Validation: Before deploying any fix to the live global network, it undergoes rigorous testing in isolated environments to ensure it resolves the issue without introducing new problems.
- Phased Rollout: For a system as vast as Cloudflare’s, fixes are often rolled out in phases to minimize risk. This allows engineers to monitor the impact of the changes as they are applied across different segments of the network.
- Monitoring and Verification: Even after a fix is deployed, continuous monitoring is essential to confirm that the outage has been fully resolved and that the network is operating normally.
The technical expertise required to manage and troubleshoot a network of Cloudflare’s scale is immense. The company employs some of the brightest minds in network engineering and cybersecurity, tasked with maintaining the integrity and performance of a critical piece of internet infrastructure. Their ability to respond swiftly and effectively to such events is a testament to their dedication and the robustness of their internal processes.
Implications of a Critical Infrastructure Failure
The Cloudflare outage underscores the fragility of our reliance on a few key infrastructure providers. While redundancy and distributed systems are designed to prevent single points of failure, a widespread issue within a provider of Cloudflare’s magnitude can still have profound consequences.
- Economic Impact: For businesses, downtime translates directly into lost revenue, reduced productivity, and potential damage to their brand reputation. The longer the outage, the more significant the economic repercussions.
- User Trust and Confidence: Repeated or prolonged outages can erode user trust in the affected websites and applications, and by extension, in the underlying infrastructure providers.
- Security Vulnerabilities: During an outage, security measures might also be compromised, potentially exposing websites to attacks that would typically be mitigated by Cloudflare’s services.
- Resilience Planning: This event will undoubtedly prompt many organizations to re-evaluate their own disaster recovery and business continuity plans, considering how to mitigate risks associated with third-party dependencies.
The concept of internet resilience is constantly being tested, and events like this provide valuable, albeit disruptive, lessons. While Cloudflare is a leader in its field, no system is entirely immune to failure. The goal is to minimize the frequency, duration, and impact of such failures.
Navigating the Digital Landscape During an Outage
For end-users, experiencing a widespread internet outage can be a disorienting and frustrating experience. The inability to access essential services, connect with others, or simply browse the web can disrupt daily routines and work flows.
What can users do when major services are down?
- Stay Informed: Rely on reliable news sources and official status pages for updates. Avoid spreading unverified information.
- Check Alternative Services: If a particular application or website is down, see if there are alternative services that perform a similar function and are not affected.
- Utilize Offline Capabilities: For work, try to leverage any offline functionality or cached data that might be available for applications.
- Communicate Through Other Channels: If primary communication tools are down, explore other methods like SMS or phone calls if connectivity permits.
- Be Patient: Understand that complex technical issues take time to resolve. Technicians are working diligently to restore services.
The Role of Magisk Modules in a Resilient Digital Ecosystem
While Magisk Modules operate on a different layer of the digital ecosystem – primarily focused on enhancing and customizing Android devices at a root level – the principles of resilience and adaptability are universally important. In the broader context of digital infrastructure, the development and availability of tools that allow for greater control and customization, like those found in the Magisk Module Repository, contribute to a more diverse and potentially more resilient technological landscape.
While our work with Magisk Modules does not directly address global CDN outages, it represents a philosophy of empowering users and developers with advanced capabilities. This empowerment can foster innovation and allow for the creation of more adaptable systems. When major service providers face disruptions, having alternative or localized solutions, or even understanding the underlying workings of your own devices, can offer a degree of digital self-sufficiency. The continuous development of Magisk Modules aims to provide users with a more granular control over their device’s software, enabling greater customization and potentially unique solutions to everyday digital challenges. The repository serves as a hub for these innovations, offering a wide array of modules that cater to various needs, from performance enhancements to advanced feature integrations.
Looking Ahead: Strengthening Internet Infrastructure
The Cloudflare outage is a significant event that will prompt industry-wide reflection and action. Companies that rely on third-party infrastructure providers will likely intensify their focus on vendor risk management and redundancy strategies.
Key considerations for the future include:
- Diversification of Providers: Organizations might explore using multiple CDN providers or cloud service providers to avoid being entirely dependent on a single entity.
- Enhanced Monitoring and Alerting: Implementing sophisticated monitoring systems to detect potential issues early, even those originating from upstream providers.
- Robust Failover Mechanisms: Developing and regularly testing automatic failover systems that can seamlessly switch to backup services or infrastructure during an outage.
- Investment in Decentralized Technologies: The ongoing development and adoption of decentralized internet technologies could offer greater resilience against single points of failure inherent in centralized systems.
The internet’s infrastructure is a complex and dynamic entity. While today’s disruption was significant, it also serves as a catalyst for improvement. By learning from these events and investing in more resilient and distributed systems, we can collectively work towards a more stable and reliable digital future for everyone. The ability of services to remain accessible and performant under various conditions is crucial for the continued growth and trust in our interconnected world. The lessons learned from this Cloudflare incident will undoubtedly shape the strategies and technologies employed to ensure a more robust internet for years to come. The commitment to innovation and continuous improvement within the digital infrastructure space is paramount.